KNN - צעדים ראשונים בקלסיפיקציה

הקדמה:
אלגוריתם KNN הוא אלגוריתם קלסיפיקציה היכול לקטלג בצורה די יפה דאטא עם 2 סוגי תוויות.
הפשטות שלו מגיע משני מקומות:
1) הצורה שבה הוא עובד
2) חוסר הצורך שלו בחישובים התחלתיים - כלומר, כל החישובים שהאלגוריתם עושה נעשים רק שמגיע דוגמא חדשה.
נרחיב על כל נקודה:
1) הצורה שבה הוא עובד:
בקצרה, האלגוריתם עובד בצורה הבאה:
a) קבלת כל הדאטא המשמש אותנו לאימון - זהו דאטא מסווג כבר ( כלומר, יש לו כבר תווית, אנו לא צריכים לחזות אותה ) ואחסונו.
b) קבלת רכיב חדש, לא מסווג, וסיווגו לפי הסתכלות על k השכנים הכי קרובים של אותה תווית, והכרעה לפי איזה תווית יש הכי הרבה בין אותם שכנים ( במקרה של k זוגי, תיקו מוכרע על ידי כלל ארביטררי אך קונסיסטטי ).
2) חוסר הצורך שלו בחישובים התחלתיים:
נשים לב, כי המקום היחיד שהיה צריך בו לחשב משהו הוא בשלב b, כאשר חישבנו את המרחק.
כאשר תלמדו עוד אלגוריתמי חיזוי, אתם תראו שזה הרבה פעמים לא במצב, וצריך איזשהו עיבוד על הדאטא לפני.
ההרחבה על הנקודות האלו מעלה מספר שאלות ברורות וחשובות:
1) איך מחשבים מרחקים על דאטא?
2) איך בוחרים את k?
נענה:
1) חישוב מרחק על דאטא - המרחק האוקלידי:
על מנת לחשב מרחק, נצטרך קודם כל למקם את דאטא האימון על איזשהו מרחב:
סט האימון שלנו יכול להגיע בהרבה צורות, עם הרבה פרמטרים מהרבה סוגים.
מכיוון שאנו יכולים לעשות חישובים משמעותיים רק על דאטא מספרי, עם משמעות של מרחק בין רכיבים שונים בו ( למשל, אם יש לי משתנה קטגוריאלי בדאטא, עם קטגוריות 1,2,3,4, אז המרחק בין קטגוריה 1 לקטגוריה 4 הוא לא 3, הוא פשוט לא קיים כי מרחק בין קטגוריאלים לרוב לא רלוונטי ), נרצה ליצור את ווקטורי האימון כווקטור העמודות עם דאטא מספרי שכזה.
יכול להיות לנו מספר רב של עמודות כאלו,וזה ייצור לנו ווקטורי אימון ממימד גבוה. מכיוון שלא תמיד ברור איך מחשבים מרחק במימדים גבוהים נלמד את המושג מרחק אוקלידי.
המרחק האוקלידי הוא הדרך הפופולרית ביותר למדוד את המרחק בין שני נקודות במרחב. הוא מוגדר כסכום הריבועים של ההפרשים בין הקואורדינטות של הנקודות.
לדוגמה, המרחק בין שני ווקטורים p,q ממימד n הוא:

יותר קל להבין את זה וויזואלית על ידי הסתכלות על המקרה הדו מימדי, והבנה שהמרחק נגזר ישירות ממשפט פיתגורס:
יהיו שני ווקטורים p,q ממימד 2, המרחק בניהם הוא:

2) איך בוחרים את k:
על מנת שהאלגוריתם יעבוד, אנו צריכים לבחור k מתאים, הנותן לנו את התוצאה הכי טובה. ישםנ עשרות דרכים לבחירת k אופטימלי, ואנו נתמקד בדרך הידועה ביותר - מציאתו על ידי cross validation.
cross validation הוא מושג בלמידת מכונה, המשתמש לשיערוך של מודלים.
מה שהוא עושה בעצם הוא חילוק דאטא האימון לשני חלקים - חלק אימון וחלק בדיקה ( train and test ). לאחר מכן, אנו נאמן את המודל שלנו על חלק האימון ( במקרה שלנו, כמו שראינו ממקודם, הכוונה באימון היא פשוט קבלת הדאטא ), ונבדוק אותו על חלק הבדיקה.
בדיקה נעשית בצורה די פשוטה - על כל נקודה בחלק הבדיקה מפעילים את האלגוריתם ( במקרה שלנו הוא יהיה KNN ) ובודקים:
האם הוא הצליח לחזות נכון את התוויות?:
כן? - הוסף לניקוד 1
לא? - הוסף לניקוד 0
השיערוך הוא אחוז ההצלחות מכלל הבדיקות.
לאחר מכן אנו חוזרים על התהליך פעם אחרי פעם, עד שעוברים על כל הדאטא. והשיערוך הסופי של אותו k נקבע על ידי ממוצע השיערוכים הפרטיים.
לפניך וויזואליציה טובה שמסבירה זו: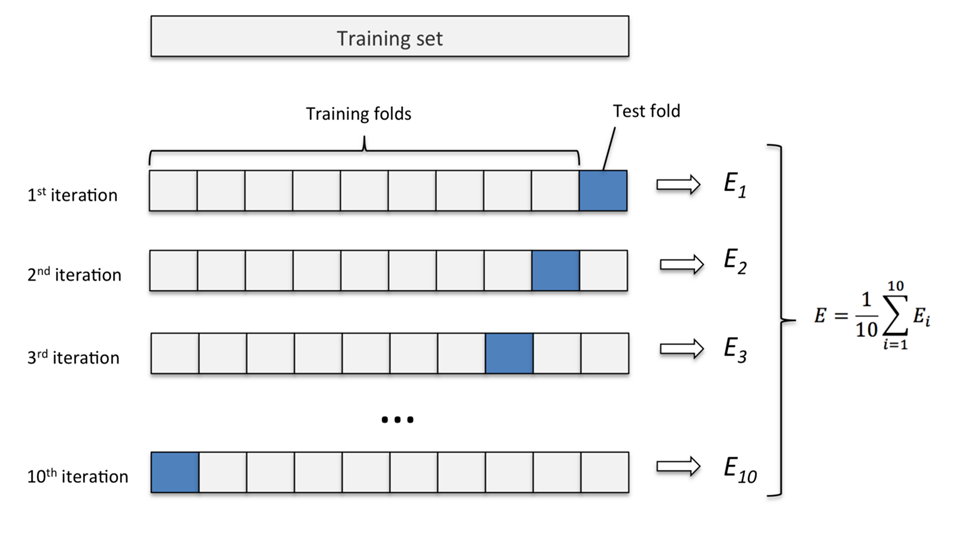
הk נכנס לתמונה על ידי הרצת מספר רב של cross validation עם ערכי k שונים. לאחר הרצה של כל ה kים, אנו נבחר את ערך הK שנתן לנו את הערך הגבוה ביותר.
לסיכום:
אלגוריתם KNN הוא אלגוריתם קלסיפיקציה פשוט ויעיל המסוגל לקטלג נתונים עם שתי תוויות. הוא פועל על ידי בחירת k השכנים הקרובים ביותר לנתון חדש ולאחר מכן שיוך הנתון החדש לאותה תווית כמו השכנים הקרובים ביותר.
הערך של k הוא פרמטר של אלגוריתם KNN שיש לבחור בקפידה.
דרך אחת לבחור את ערך k היא להשתמש בתהליך של cross-validation. Cross-validation היא טכניקה שבה נתוני האימון מחולקים לשני חלקים: חלק אימון וחלק בדיקה. האלגוריתם מאומן על חלק האימון ונבדק על חלק הבדיקה. התהליך חוזר על עצמו מספר פעמים, וכל פעם חלק אחר של נתוני האימון משמש לבדיקה. הערך של k שמקבל את התוצאה הטובה ביותר ב-cross-validation הוא בדרך כלל ערך k האופטימלי.
